Load balancing with Elastic Load Balancer (ELB)
Load balancing refers to distributing user traffic to multiple instances.
A load balancer sits in front of your instances and distibutes traffic depending on instance load.
This diagram explains it well:
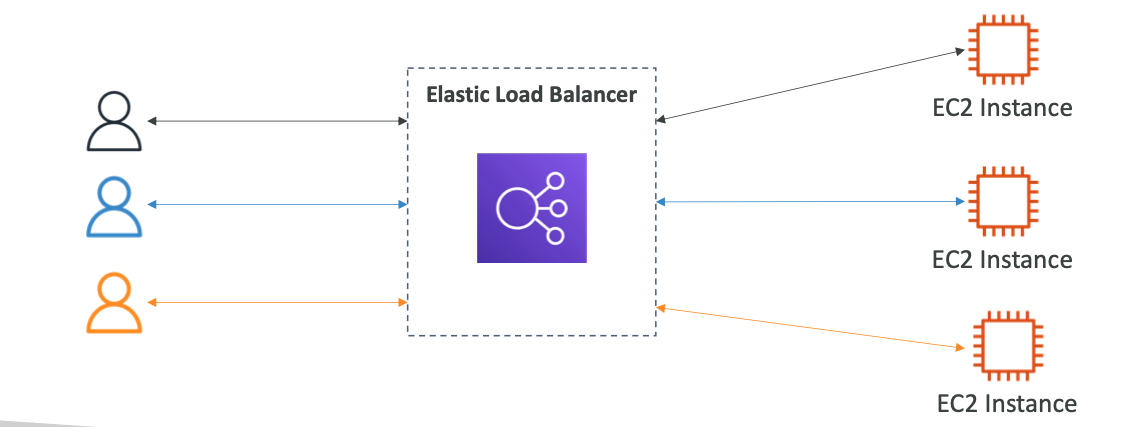
Why?
- Spreads load
- Single point of access using DNS
- Failure handling
- Load balancers can check health of instances
- Load balancers check if downstream server will reply to requests
- HTTPS support
- High availability
- Can separate public and private traffic
Elastic Load Balancer (ELB)
Managed service that AWS maintains. No need to configure it yourself. Integrates with:
- EC2, EC2 auto scaling groups, ECS
- AWS Cert Manager, CloudWatch
- Route 53, AWS WAF, AWS Global Accelerator
ELB types
Different generation of EBS:
- Classic Load Balancer (old gen)
- Application Load Balancer (v2)
- Network Load Balancer (v2 new gen)
- Gateway Load Balancer - 2020 and newest
Load balancers will allow access from anywhere, but the connection betweem EBS and EC2 instances is managed through security groups so EC2 access is restricted.
Load balancer types
It’s important to note that ELB is the overall service, but there are different types of load balancers for different purposes, as noted below
Application Load Balancer (ALB)
This load balancer works at the HTTP level and allows for:
- HTTP load balancing
- Container load balancing
- HTTP/2 and WebSocket
- Redirects (HTTP > HTTPS)
Load balancing can be based on:
- Path based. /users or /posts for e.g
- Hostname (subdomains, for e.g)
- Query strings and headers
ALB is good for microservices where you want to balance load between services and each service might hit a different endpoint, subdomain, container etc
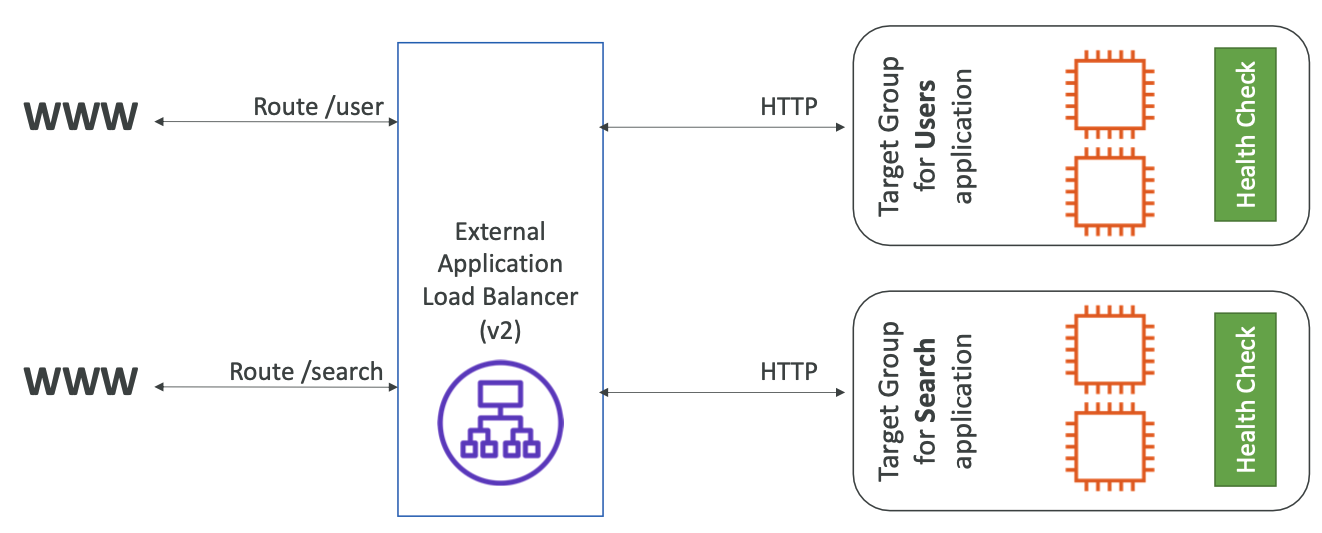
Target groups
Path routing, for example, determines which target group (a set of resources) to route request to. Target groups can be:
- EC2 instances
- ECS tasks
- Lambda functions
- IP addresses
For example query param target group routing:
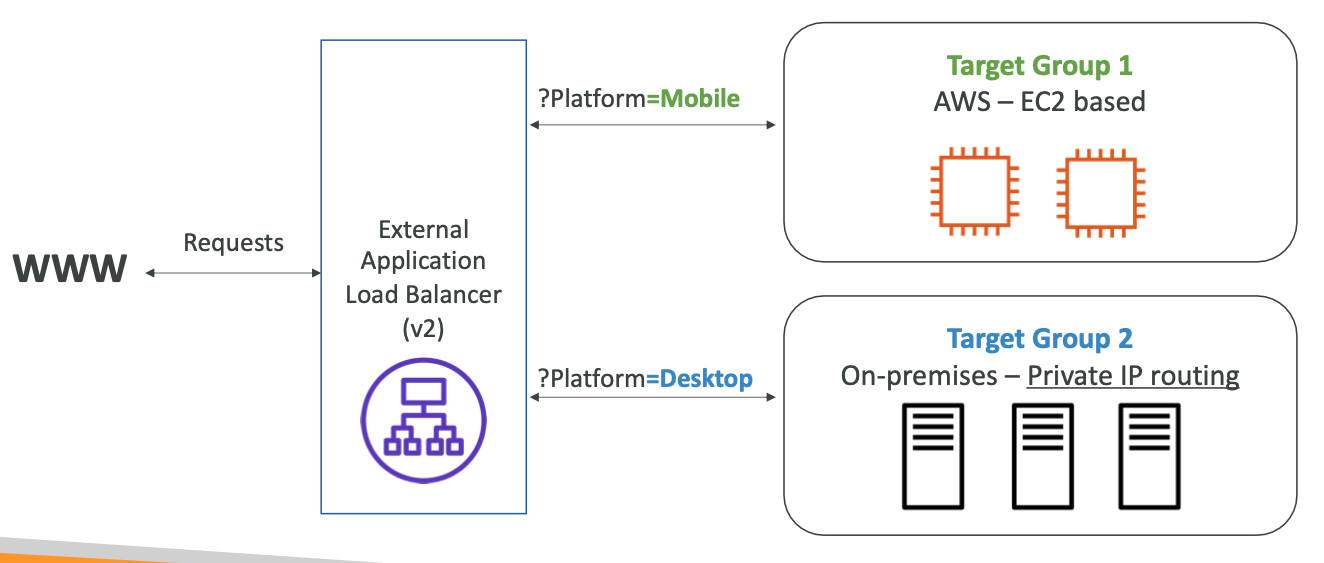
Good to know:
- ALBs get a fixed hostname
- App servers don’t see client IP directly, instead it’s passed through headers
Network Load Balancer (NLB)
This is a lower level load balancer (Layer 4) - affecting the TCP and UDP layer.
It has:
- Ultra low latency
- Handles millions of RPS
- 1 static IP per AZ and supports supports Elastic ips
Gateway Load Balancer (GLB)
- A way to scale and manage a fleet of 3rd party network applications in access
- Example: firewalls, intrustion detection
- It is a way to route all traffic through a gateway
- You can think of it as an additional layer between traffic and your applications. It allows you to analyse network traffic and possibly drop
- Operates at Layer 3 (network layer)
- It has the following functions:
- Transparent Network Gatewau - single entry/exit for all traffic
- Load Balancer - distributes traffic to virtual applications
- It uses GENEVE protocol on port 6081
GLB allows you to analyse all traffic and drop it if necessary.
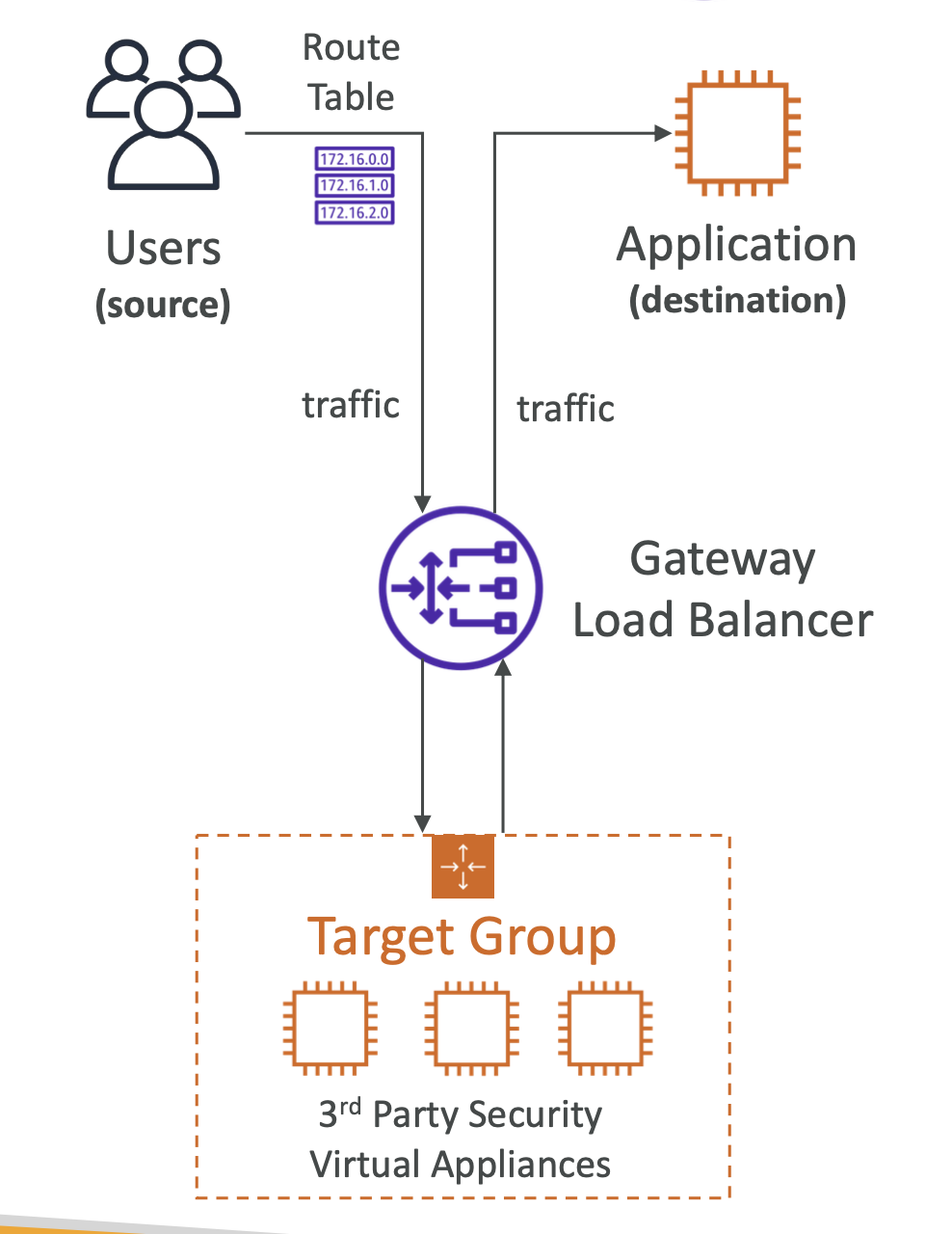
Target groups can be:
- EC2 instances
- IP addresses
Sticky Sessions
Sticky sessions is a way to keep the same user on the same instance even when using a load balancer.
Usually a load balancer will distribute traffic among different instances, but if you want to keep the same user on the same instance, for example to keep their session information, you can use sticky sessions.
It’s controlled using a cookie, which is either:
- A custom cookie
- A default cookie set by Sticky Sessions
Cross-Zone Load balancing
Cross-zone load balancing allows you to distribute load balancer traffic across different AZs. It can be turned on and off per load balancer.
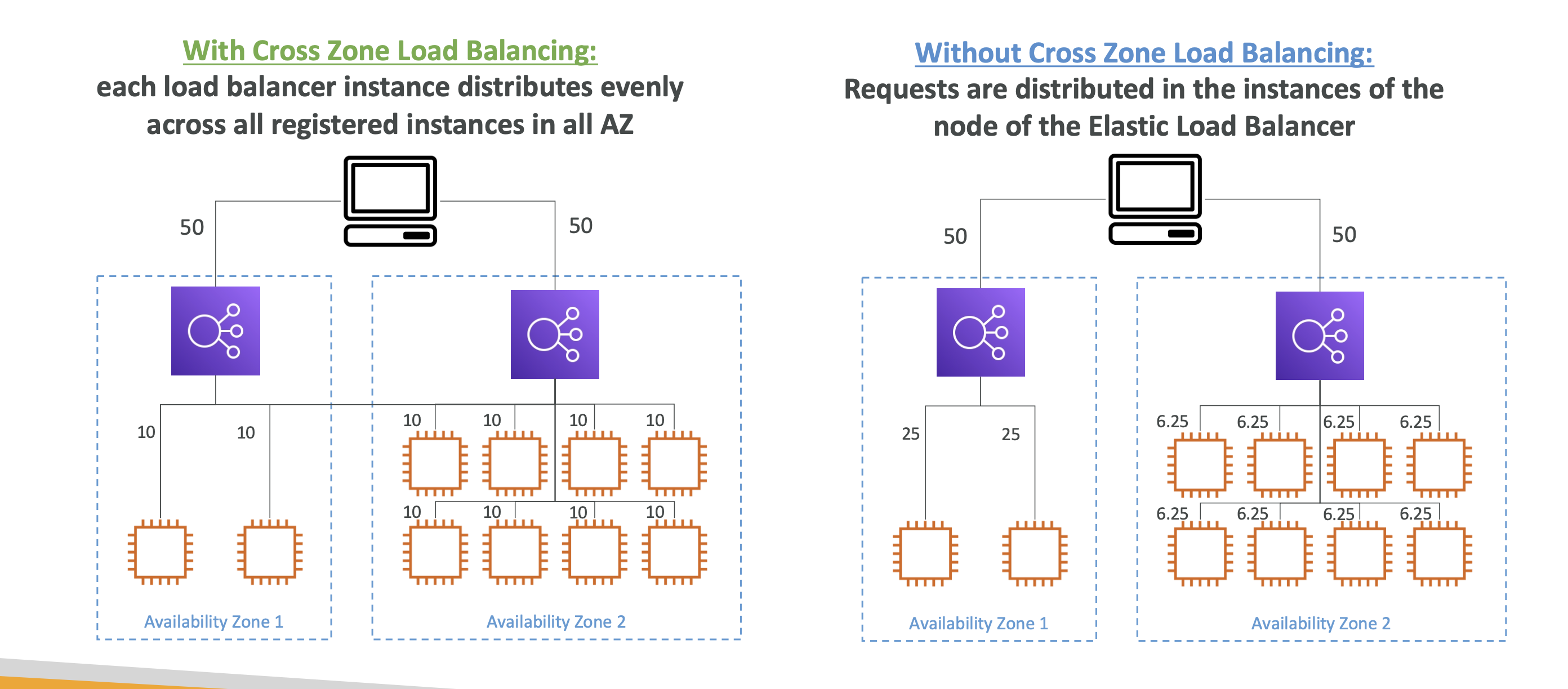
If it’s turned on, all traffic will be spread evenly across AZs. Otherwise it won’t.
It’s automatically on for ALBs, but needs to be turned on manually for NLBs and GLBs and will incur a charge for the latter two.
Connection Draining
This gives the request time to complete while instance is de-registering or “unhealthy”.
It will stop sending requests to instances that are de-registering.
Can be set from 1 to 3600 seconds.
Auto Scaling Group (ASG)
An ASG adds or remove more instances depending on user load. It’s referred to as:
- Scale out (adding EC2 instances)
- Scale in (removing EC2 instances)
They are free! You only pay for the infra you get. They also work OOTB with load balancers, which connect automatically to new instances added.
You get to define:
- Minimum capacity
- Desired capacity
- Maximum capacity
You define a launch template that contains all EC2 info that are used as parameters to launch new instances.
CloudWatch alarms
When alarms are triggered (avg CPU or custom metric) the Auto Scaling Group can be enacted.
Auto Scaling Groups - Scaling Policies
Scaling policies allow us to define under what conditions to scale.
Dynamic Scaling
- Target Tracking Scaling: define metric (for e.g CPU usage) and ASG will scale out or in to match that metric
- Step Scaling: This scales depdning on CloudWatch alarm trigger, for e.g CPU > 70%, add 2 units
- Scheduled scaling: Scale based on times. Based on usage patterns
Predictive Scaling
ASG analyses historical load, forecasts load and then scales
Good metrics to scale on
- CPU utilisation
- RequestCountPerTarget: make sure requests per instance is stable
- Average network in/out
- Any custom metric!
Scaling cooldown
After removing/adding instances, which is a 5 minute cooldown where no instance changes can be made. Allows for instance stablisation